
총 회원수 구하기
SELECT COUNT(email) FROM name.table;
모든 회원은 이메일을 가지고 있다는 가정하에 email로 설정(혹시 아니라면 다른거로 해도 됨)
null값은 카운트 하지 않는다.
이렇게 하면 null값이 있는지 없는지 확인을 매번 해줘야 하니 아래처럼 한다
SELECT COUNT(*) FROM name.table;
이렇게 하면 전체 로우 수를 리턴해준다.
가장 큰 값을 알고싶은 경우는
SELECT MAX(height) FROM name.table;
height값중 가장 큰 값을 리턴해준다.
반대로 가장 낮은 값은
SELECT MIN(height) FROM name.table;
min으로 해주면 된다.
평균값을 구하고 싶을때는
SELECT AVG(height) FROM name.table;
이때 만약 null값이 있다면 빼고 평균을 구해주게 된다.
합계를 구하려면
SELECT SUM(height) FROM name.table;
표준편차
SELECT STD(height) FROM name.table;
- ABS() 함수 - 절대값을 구하는 함수
- SQRT() 함수 - 제곱근을 구하는 함수
- CEIL() 함수 - 올림 함수
- FLOOR() 함수 - 내림 함수
- ROUND() 함수 - 반올림 함수
null 다루기
null값에 해당하는 것을 불러오기
SELECT * FROM name.table WHERE address IS NULL;
반대로 null이 아닌 값들을 불러오려면
SELECT * FROM name.table WHERE address IS NOT NULL;
null인 값 변경해서 불러오려면
SELECT COALESCE(height,"X") FROM namc.table;
동작법은 간단하다 null이 아니면 그대로 리턴해주고 null이면 뒤에 적은 문자로 돌려준다.
null에 대해 알아야할 것
- IS NULL 과 = NULL은 다르다.
NULL은 어떤 값이 아니기 때문에 애초에 등호(=)를 사용해서 어떤 값과 비교할 수 있는 대상이 아닙니다. 그래서 = NULL은 절대 TRUE일 수가 없죠. 그래서 IS NULL이라는 키워드가 별도로 마련된 겁니다. 앞으로 NULL인지를 확인할 때는 = NULL을 쓰면 안 되고, 반드시 IS NULL을 써야한다는 점을 꼭 기억하셔야 합니다.
- NULL에는 어떤 연산을 해도 결국 NULL
만약 나이를 잘못 설정해둬서 -11, 200 이런식으로 들어왔을 경우
잘못된 데이터를 제외하고 조회
SELECT AVG(age) FROM name.table WHERE age BETWEEN 5 AND 100;
이런식으로 해서 5~100사이만 가져다 사용
만약 주소에도 이상한게 있다 그러면 밑에 사진처럼 정상 데이터의 공통점을 찾는다.

SELECT address FROM name.table WHERE address LIKE "%호"
컬럼끼리의 계산
컬럼끼리는 아래의 연산을 사용해 산술계산을 할 수 있다.
| + | 더하기 |
| - | 빼기 |
| * | 곱하기 |
| / | 나누기 |
| % | 나머지 구하기 |
SELECT height, weight ,weight / height*height FROM name.table;
이런식으로 사용 가능한데 만약 여기서 height 이나 weight이 null일 경우 null은 어떤 연산을 해도 null이니 null이 나오게 된다.
null이 들어간 계산은 항상 null
컬럼에 alias 붙이기
위처럼 계산식을 사용한 경우
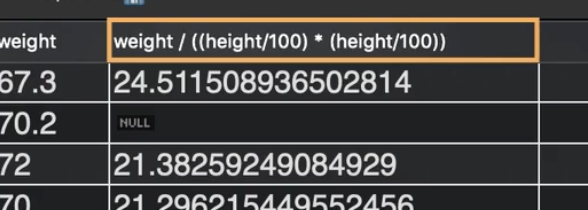

이렇게 컬럼 이름이 나오게 되는데 이를 한눈에 알아보기 쉽게 변경해줄 수 있다.
우측 사진처럼 작성해주면 바꿀 수 있다
이렇게 컬럼에 다른 이름을 붙이는 것을 alias라고 한다.
이는 우리말로 별명,별칭이라는 뜻이다.
여기서 AS를 생략할 수 있는데 가급적이면 붙여주는것이 좋다.
나중에 길어지면 가독성이나 그런 측면에서..
또 CONCAT을 사용할 수 있는데 아래를 보면..

height에는 cm을 , weight에는 kg를 붙여서 키와 몸무게라는 컬럼으로 보여준다는 것이다.
아래처럼 CASE를 사용해서
WHEN ~~~ 면 THEN ~~~로 표시

CASE문을 괄호로 감싼 후 AS를 사용해 컬럼 이름을 변경 가능하다1
고유값만 보기
DISTINCT : 고유한
만약
SELECT DISTINCT(gender) FROM namc.table;
이렇게 출력하면 고유한 값인 m과 f만 나올것이다
이 둘 중 하나이기 때문에..
만약 address로 하려고 하면 주소는 모두 고유한 값이기 때문에 그대로 나오게 될 것입니다.
이 때 서울, 경기 이렇게 하려고 한다면
SELECT DISTINCT(SUBSTRING(address, 1,2)) FROM namc.table;
SUBSTRING은 문자열의 일부를 추출하는 함수로 위의 경우에는 1번째부터 2개 를 자른다는 것이다.
이외의 함수는
LENGTH() 함수
LENGTH() 함수는 문자열의 길이를 구해줍니다.
UPPER(), LOWER() 함수
UPPER()는 문자열을 모두 대문자로 바꿔서 보여주는 함수이고, LOWER()는 문자열을 모두 소문자로 바꿔서 보여주는 함수입니다.
LPAD(), RPAD() 함수
이 두 함수는 문자열의 왼쪽 또는 오른쪽을 특정 문자열로 채워주는 함수입니다.
LPAD는 LEFT(왼쪽) + PADDING(채우기)의 줄임말, RPAD는 RIGHT(오른쪽) + PADDING(채우기)의 줄임말인데요.
예를 들어 LPAD(age, 10, ’0’)는 age 컬럼의 값을, 왼쪽에 문자 0을 붙여서 총 10자리로 만드는 함수입니다. 보통 어떤 숫자의 자릿수를 맞출 때 자주 사용하는 함수입니다. 아래 그림을 보면 무슨 뜻인지 바로 이해할 수 있습니다.
TRIM(), LTRIM(), RTRIM() 함수
LTRIM() : 왼쪽 공백 삭제
RTRIM() : 오른쪽 공백 삭제
TRIM() : 왼쪽, 오른쪽 양쪽 다 공백 삭제
그루핑
그루핑은 여러가지 그룹으로 나눈다는 뜻

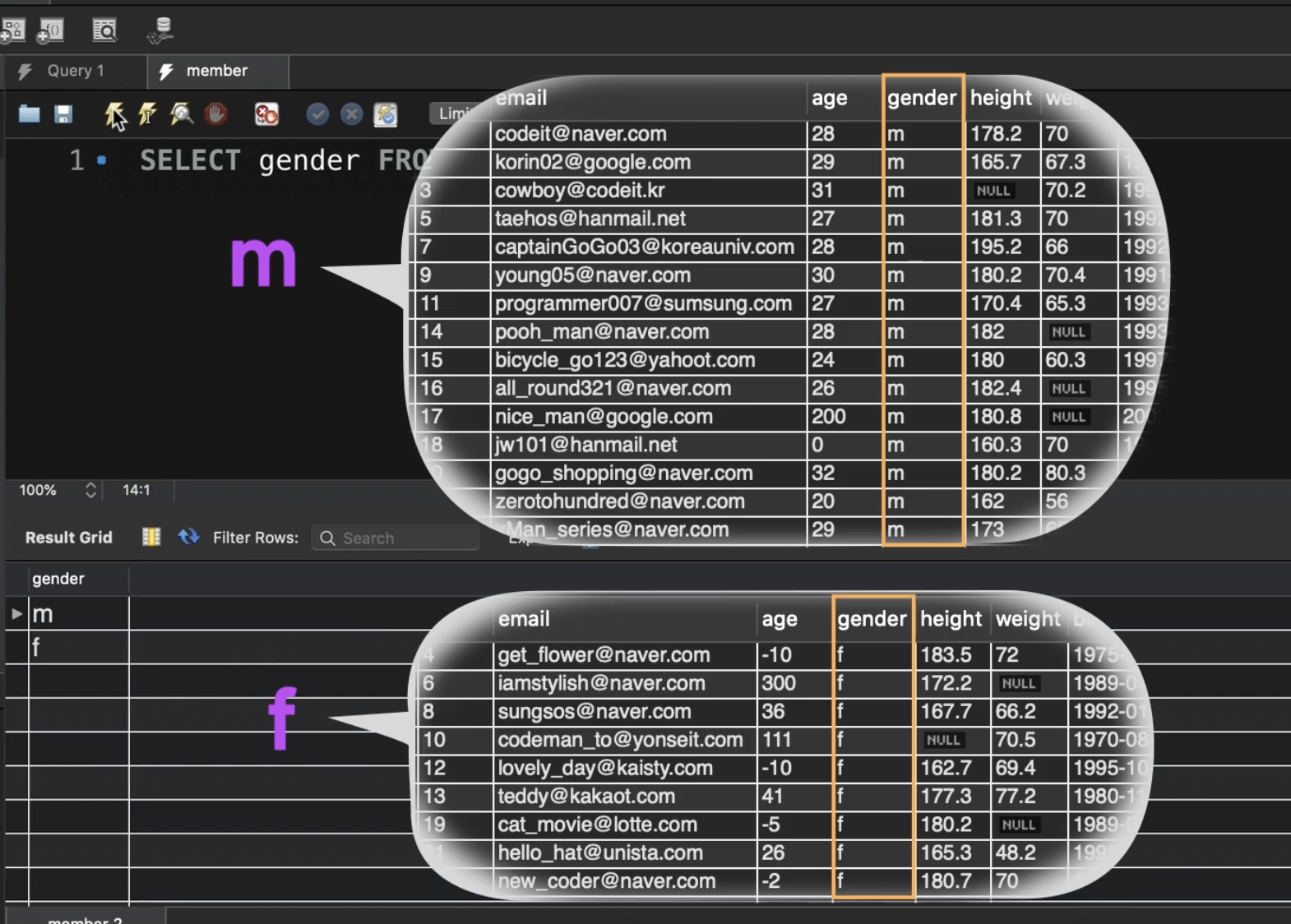
이런식으로 사용을 하고 결과가 밑에처럼 나오게 되는데
결과만 보면 절대값을 출력했을때와 비슷하다.
하지만 저 내부에는 각각 gender가 m인것들과 f인 것들로 그룹화 되어있다.
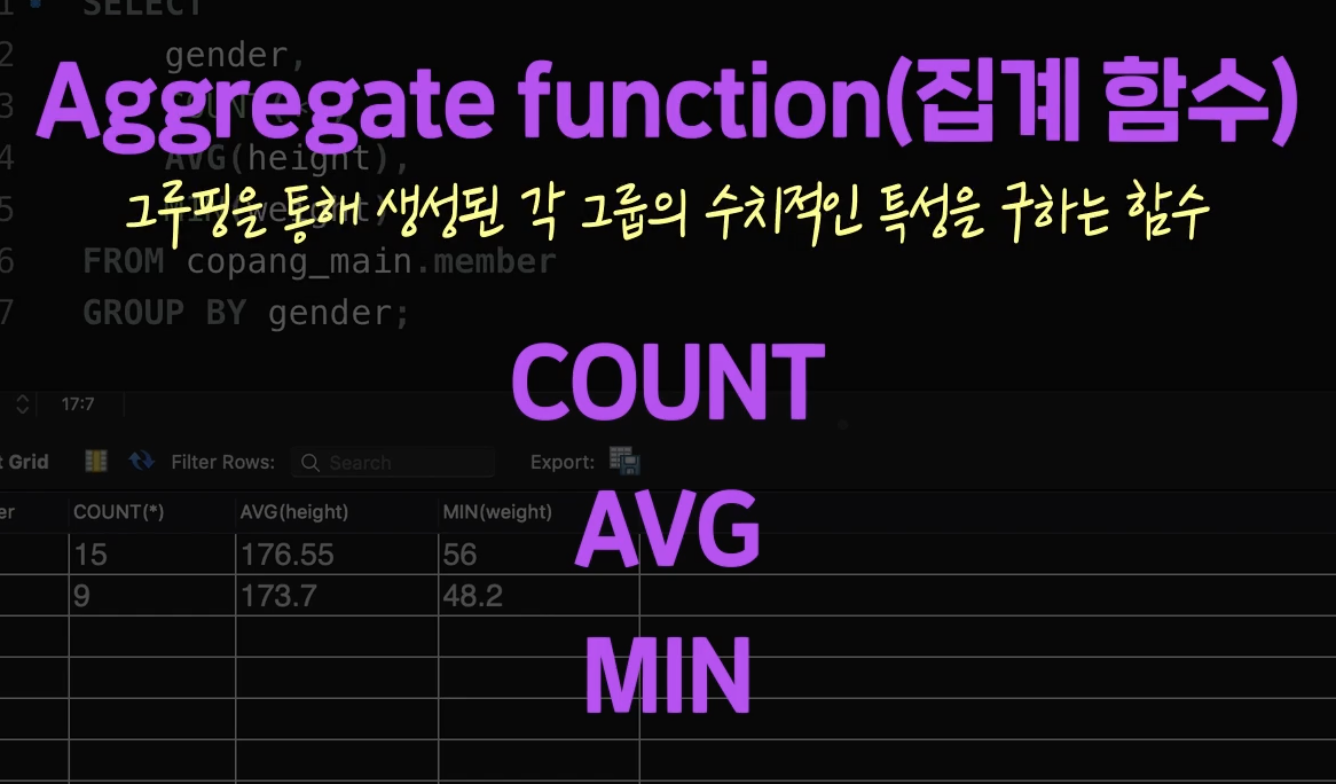
이때 만약 각각의 그룹의 회원수를 알고싶다면
SELECT gender , COUNT(*) FROM name.table GROUP BY gender;
이렇게 하면 그룹으로 나눠진 m과 f 그룹에서 각각 COUNT(*) 가 실행이 된다.
이런걸 집계함수라고 하는데
만약 주소를 이용해 그룹을 만들고 싶다면..
이전에 주소의 첫 두글자를 사용해 그룹을 만들었던 것 처럼 SUBSTRING을 사용해 그룹화 해줍니다.
SELECT SUBSTRING(address,1,2) FROM name.table GROUP BY SUBSTRING(address,1,2);
그루핑의 기준을 하나로만 했었는데, 여러개로 할 수 있다.
사용법은 간단하다
SELECT SUBSTRING(address,1,2) FROM name.table GROUP BY SUBSTRING(address,1,2),gender;
이렇게 GROUP BY 뒤에 , 로 이어 붙이면 된다.
여기서 그룹 이름이 ‘서울’인 그룹만 보고싶다면
SELECT SUBSTRING(address,1,2) AS res FROM name.table
GROUP BY SUBSTRING(address,1,2),gender
HAVING res = "서울";

여기서 조건을 더 추가하고싶다면
SELECT SUBSTRING(address,1,2) AS res FROM name.table
GROUP BY SUBSTRING(address,1,2),gender
HAVING res = "서울" AND gender = "m";
AND를 써준다.
여기서 WHERE와 비슷하다 생각할 수 있는데
WHERE : 처음 생성된 로우들 중 필터링
HAVING : 그룹화된 애들중 필터링
이다.
다시 돌아가서 전체를 보면 그룹 이름이 null인 경우도 있는데 이를 제외하려면
SELECT SUBSTRING(address,1,2) AS res FROM name.table
GROUP BY SUBSTRING(address,1,2),gender
HAVING res IS NOT NULL;
마지막으로 정렬까지 해준다면
SELECT SUBSTRING(address,1,2) AS res FROM name.table
GROUP BY SUBSTRING(address,1,2),gender
HAVING res IS NOT NULL
ORDER BY res ASC,gender DESC
;
GROUP BY를 사용할 때는,
SELECT 절에는
- GROUP BY 뒤에서 사용한 컬럼들 또는
- COUNT(), MAX() 등과 같은 집계 함수만
쓸 수 있다는 규칙입니다. 이건 거꾸로 말해 GROUP BY 뒤에 쓰지 않은 컬럼 이름을 SELECT 뒤에 쓸 수는 없다는 말입니다.
GROUP BY 뒤에 쓰지 않은, 그러니까 그루핑 기준으로 사용하지 않은 컬럼명을 SELECT 절 뒤에 써서 조회하려고 하면,각 그룹의 row들 중에서 해당 컬럼의 값을 어느 row에서 가져와야할지 결정할 수가 없습니다.
- GROUP BY 절 뒤에 쓴 컬럼 이름들만, SELECT 절 뒤에도 쓸 수 있다.
- 대신 SELECT 절 뒤에서 집계 함수에 그 외의 컬럼 이름을 인자로 넣는 것은 허용된다.
GROUP BY와 함께 알면 좋은것
GROUP BY 맨 뒤에

WITH ROLLUP을 적어주게 되면
아래처럼 gender은 null이지만 각 지역별로 총 몇명인지 나오게 된다

GROUP BY 뒤 기준들의 순서에 따라 WITH ROLLUP 의 결과도 달라집니다.